 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhilip Edmonds
Choosing the Word Most Typical in Context Using a Lexical Co-occurrence Network
Nov 02, 1998
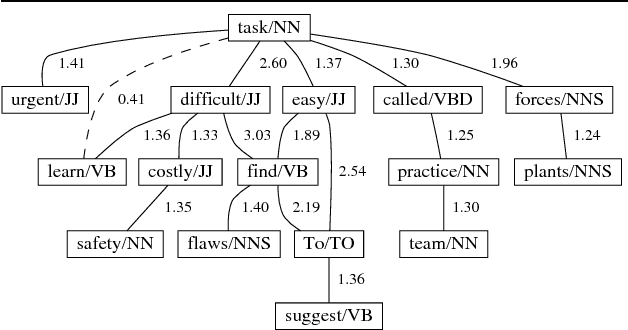

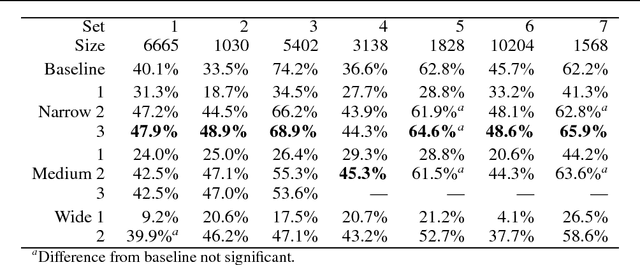
This paper presents a partial solution to a component of the problem of lexical choice: choosing the synonym most typical, or expected, in context. We apply a new statistical approach to representing the context of a word through lexical co-occurrence networks. The implementation was trained and evaluated on a large corpus, and results show that the inclusion of second-order co-occurrence relations improves the performance of our implemented lexical choice program.
* 3 pages, LaTeX2e, 1 ps figure, uses mathptm.sty, colacl.sty, psfig.sty
Translating near-synonyms: Possibilities and preferences in the interlingua
Nov 02, 1998
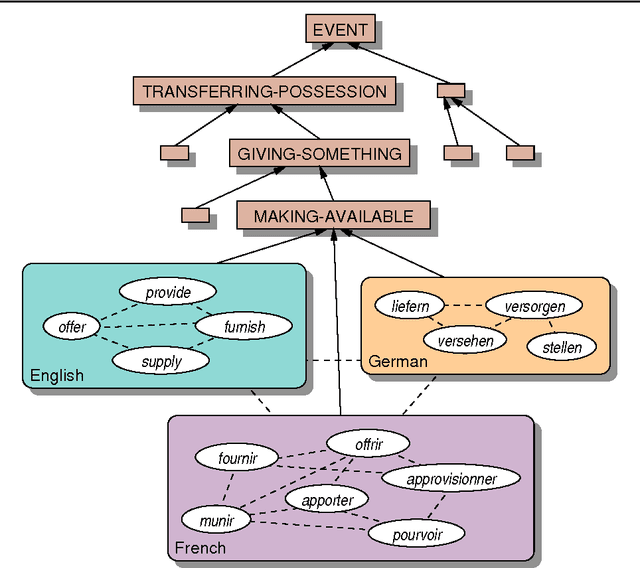

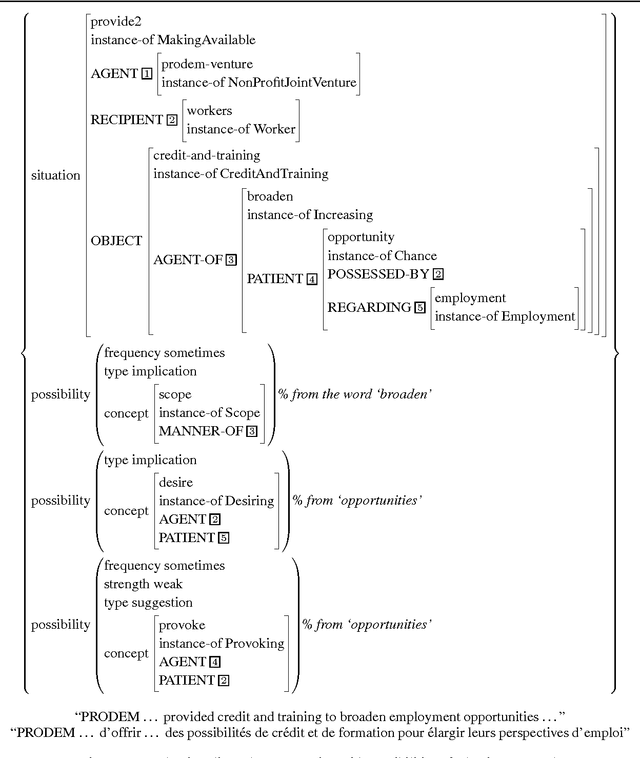
This paper argues that an interlingual representation must explicitly represent some parts of the meaning of a situation as possibilities (or preferences), not as necessary or definite components of meaning (or constraints). Possibilities enable the analysis and generation of nuance, something required for faithful translation. Furthermore, the representation of the meaning of words, especially of near-synonyms, is crucial, because it specifies which nuances words can convey in which contexts.
* 8 pages, LaTeX2e, 1 eps figure, uses colacl.sty, epsfig.sty, avm.sty, times.sty